Data source configuration¶
qbo insights allows conversational access to data in a relational database without the need for the user to know SQL. In order to provide this access, qbo insights has a unique process for understanding the contents of a database, deciding on the kinds of queries that can be asked of the database, exposing the possible queries to the end-user through auto-completions and auto-suggestions, and training the natural language processing to understand users’ utterances in the context of the data present in the database. Most of this process is automated; but this process still benefits from various kinds of information and hints about the data model from a developer or data architect.
qbo insights supports a wide variety of queries on relational databases utilizing all common SQL constructs, including SELECT, WHERE, GROUP BY, ORDER BY, LIMIT, JOIN, AND, OR, NOT, LIKE, HAVING, UNION, etc. It also supports various date related functions, nested queries, queries involving multiple clauses, binning, various aggregation functions, etc. It also supports querying different kinds of tables including fact tables, dimension tables, junction tables, etc. and schemas like star and snowflake schemas.
One can hookup multiple data sources to qbo, the QueryBot. For instance, qbo could be connected to the sales database on MariaDB as well as with the inventory database on Oracle. When a user asks a question, it would be converted to a query and routed to the appropriate database for fetching the results. This assumes that entity names do not clash between the data sources. Furthermore, at this time qbo does not support queries that refer to data across data sources. If one needs to query across data sources, we recommend using technologies like Apache Presto.
In this section, we go through the configuration steps to add a new data source, select that tables that will be used by the QueryBot, and configure the data model and analytics against the selected tables.
New data source¶
When trying to add a new data source, one has to start by clicking Add a new data source card. To reach this page browse to Settings > Data Sources.

Related Videos
Add a new data source
On the resulting page, one has to enter a name for the data source and select the kind of data sources.
Note
qbo insights supports the following databases, which may be installed on-premise or on the cloud and file upload option:
Impala
JavaDB
MariaDB
Microsoft SQL Server
MySQL
Oracle Database
PostgreSQL
Presto

Note
Athena
HubSpot
Salesforce
Snowflake

Note
Excel

If your data sources are not listed above, please get in touch with helpdesk@unscrambl.com and the team might be able to assist you. Additional data sources are being added continuously.
The next screen asks for credentials corresponding to the selected data source. For JavaDB/MariaDB/Microsoft SQL Server/
MySQL/Oracle Database/PostgreSQL , for instance, this would include the hostname/IP address,
port, database name, username and password.

The additional information required for Impala is Kerberos Authentication Configuration and SSL Configuration.
For instance, this will include Service Name and Server Certificate File Path respectively.

The additional information required for Presto is Kerberos Authentication Configuration that is Service Name and Principal Name,
SSL Configuration that is Server Certificate File Path and Catalog information.

Now let’s see for cloud data sources what details are required for connection.
For connecting to cloud Athena data source Region, S3 output location, Database name,
AWS access key and AWS secret key is required.
The Region is an S3 output bucket’s location must be in the same region as the connection location.
In order to get your Access Key ID and Secret Access Key follow next steps:
- Open the IAM console
- From the navigation menu, click Users.
- Select your IAM user name
- Click User Actions, and then click Manage Access Keys
- In order to get your Access Key ID and Secret Access Key follow next steps.
- Click Create Access Key
- Your keys will look something like this:
> Access key ID example: AKIAIOSFODNN7EXAMPLE
> Secret access key example: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
- Click Download Credentials

For connecting to the cloud Hubspot data source HubSpot API key is required.
In your HubSpot account, click the settings icon settings in the main navigation bar.
In the left sidebar menu, navigate to Integrations > API key.
If a key has never been generated for your account, click Generate API key.
If you've already generated an API key, click Show to display your key.

For connecting to cloud Salesforce data source Username, Password and Security token is required.
A security token is an automatically generated key that you must add to the end of your password in order to login to
Salesforce from an untrusted network.
For example, if your password is mypassword and yourmsecurity token is XXXXXXXXXX then you must enter
mypasswordXXXXXXXXXX to log in.

For connecting to cloud Snowflake data source Account name, Database name(case sensitive) and Warehouse, Role (optional), Username and Password is required.
Account name: your account name is the full/entire string to the left of snowflakecomputing.com.
E.g. https://.snowflakecomputing.com
Database name and warehouse name on which the database is running.

For connecting to Excel files you need to define the following options. Let’s see them in detail.
Define Tables: Table1=Sheet1!A1:N25,Table2=Sheet2!C3:M53 (Use this format to define tables)
Upload file: Upload your excel file (50 MB maximum size) from your desktop.
Header: Select this if the header can be used to identify attributes.
Orientation: Vertical/Horizontal
Type detection scheme: ColumnFormat/RowScan/None
Has cross sheet references: Select this option if there is a relationship between different sheets.
Tables can be defined in the following manner for excel file having more than one sheet. Let’s suppose excel file two sheets named netflix_movies data populated from column A to I have 48 rows and netflix_series data populated from column A to K have 6235 rows.

Sheets will now be added as tables.

Various data types in Excel are interpreted by String, Double and Datetime in qbo insights. Let’s take an example. Refer to the following Excel sheet with various data formats.

These formats will be interpreted by qbo insights in the following data types.

Note
MS Excel file should be processed in qbo, any other format for eg. google sheets or Libre Office should be first converted to MS Excel file.
Verify properly the data types of various Excel columns. This step is necessary so that qbo can identify data type correctly. Convert your column type to double, date, etc., as needed.
Note that columns of type
Numberin Excel are interpreted as Double by qbo insights, even if they happen to contain only integers and columns of typeDateare interpreted as DateTime.Excel only supports String, Double and Datetime.

Note
It’s recommended to start the data from the top left and to use ColumnFormat for data types.
If extra columns are shown in your logical data model usually these columns are named A, B, C etc., Such columns can be safely deleted from the model.
If RowId gets added as a new Integer attribute, and the users can choose to delete it.
qbo insights is able to automatically fetch the schema information from the selected data source and display it to the user. The user can then select the tables that they want to query for the data source being configured.

Please note that more tables can be added later, and very often configuring the data model is an iterative process.
Data Source Settings¶
There are a few settings available for data source. Click ![]() on the right side of the data source section.
on the right side of the data source section.

Free form query configurations
qbo uses the ability of the NLP model to understand user queries with no prior training, data preparation or human-driven model building. Various options are available in the free form query configurations section. Let’s understand them in detail.
Max number of variations: In case of an ambiguity, the max number of alternative canonical query variations to be prompted to the user.
Max query prompt trial count: In case of an unclear query with missing attributes, the max number of the same clarification question to be asked to the user for the same missing attribute. If the user cannot provide a valid answer to fill the missing attribute within the trial count, qbo will stop trying to resolve the current query and ask for the next one.
Query prompt loop breaker intent: In case of an unclear query with missing attributes, the name of the resolved intent for the user input to break the clarification questions loop. After breaking the clarification loop, qbo will ask for the next query.
Query results expansion rate: The canonical query results returned by the similarity recognizer are scored according to their attributes. The highest scoring result is returned as the similarity result. If there are query results with very close scores, the query results expansion rate serves to add these query results to the similarity result as the alternatives.
Max branching depth: Explanation to be added
Max number of entities: Explanation to be added
Max number of recursive branches: Explanation to be added
Response: It defines the automatic response to be given to the user, in case the user’s query matches the intent.
Intents: It defines the intent names, which will be answered with the automatic response. The intent recognition rules are defined in the “Rule based intent recognizer configuration intent rules”.
Rule based intent recognizer configuration intent rules
Intent: The name of the intent
Pattern: The pattern to be recognized as an intent. The user’s query is matched against this pattern.
Max branching depth: Maximum depth of the grammar tree used to build a query template. Deeper trees might result in more complex query templates.
Max number of entities: Maximum number of entities allowed to be present in a query template.
Max number of recursive branches: Maximum number of allowed recursions in the same branch of the grammar tree. Usually used to implement conjunctions of the same grammar clause.

Sample Queries
This option is used to provide a list of possible example queries that current qbo instances can answer. These sample queries are picked by the help command in MS Teams.

Session timeout expiration
This option is used to set a timeout for the qbo server in minutes.

Configuring the data model¶
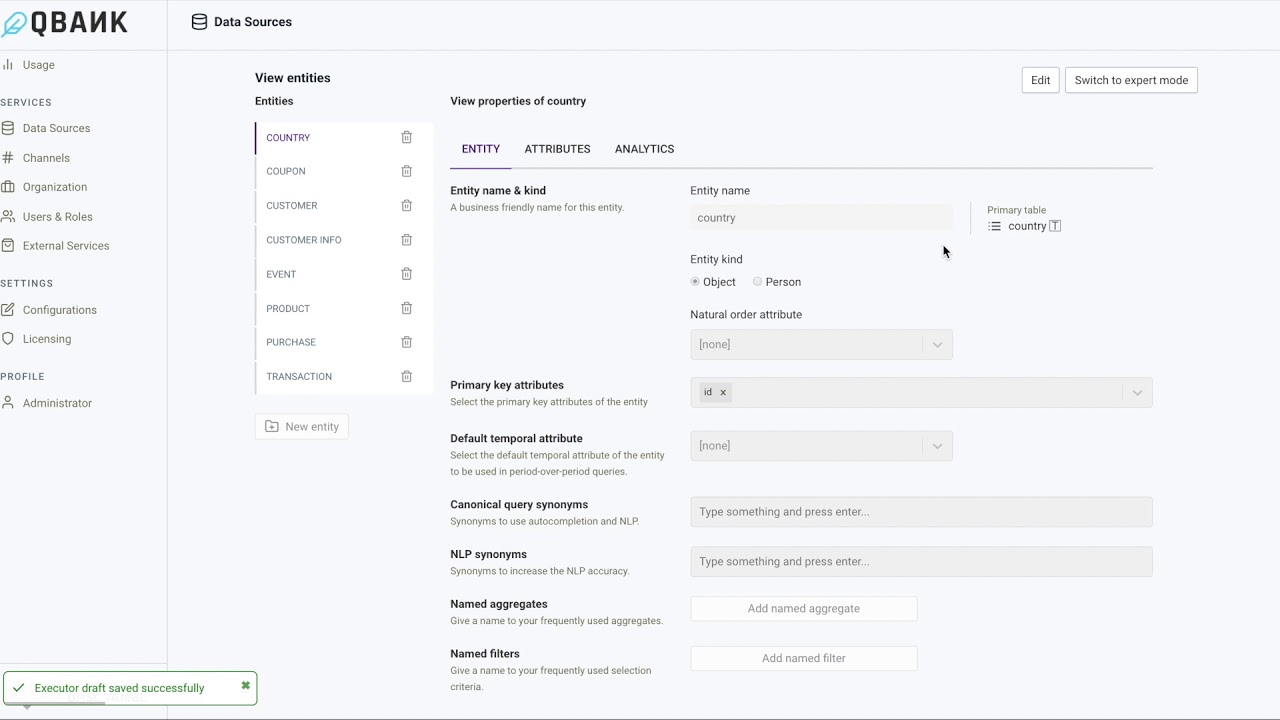
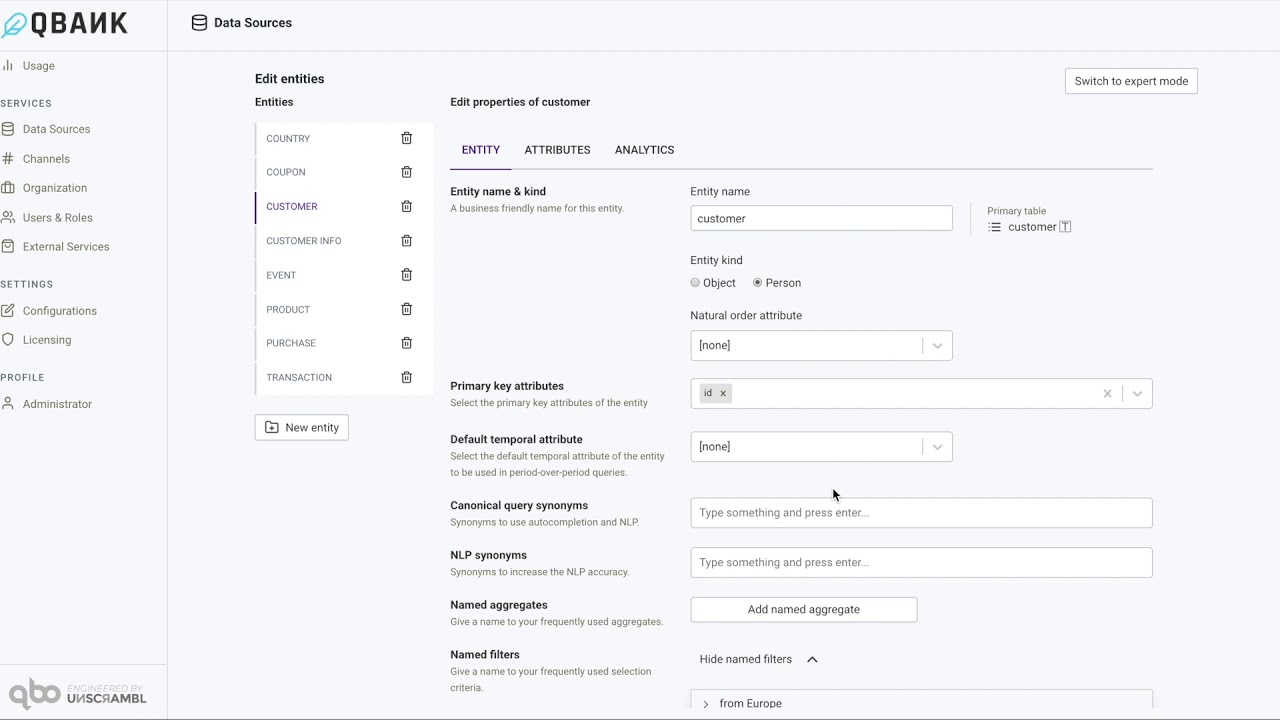
The next step is where one can start editing the entities, specify relationships, etc. Each of the selected table in the step above is treated as an entity. One can use this step of the data model configuration to manage various aspects of the entity (e.g. entity kind, primary keys, default temporal attribute, etc.), add/remove attributes to the entity and also configure analytics for the entity. We will going through such configuration in this section.
One can start by selecting the entity to be edited from the listing on the left. Each entity has configurations for the entity, the attributes of the entity and the analytics associated with the entity. These 3 are grouped as 3 tabs on the top of the panel, for each entity.

Note
There is an expert mode available using which you can see JSON format of the data model. Click on the button on the top right-hand side
Switch to expert mode. There are three sections visible showing entities, attributes and their relations. These 3 are grouped as 3 tabs on the top of the panel, for each entity using three models.Entity-Relationship Model
Querybot Entity-Relationship Model
Querybot Relational Entity Mapping

Entity configurations¶
Here is a quick description of the various configurations associated with an entity:
| Configuration | What it does? |
|---|---|
| Entity Name | This is the name used to refer to the entity. If country is the entity name then the corresponding question that can be answered in the guided mode would be: What are the countries? and other variants of the question. |
| Entity Kind | An entity could be of type object or type person. One would typically tag entities that refer to humans (e.g. a customer) as a person entity. An entity tagged as a person will have have the guided questions starting with who instead of what. For instance the question would be Who are the customers with gender female?. |
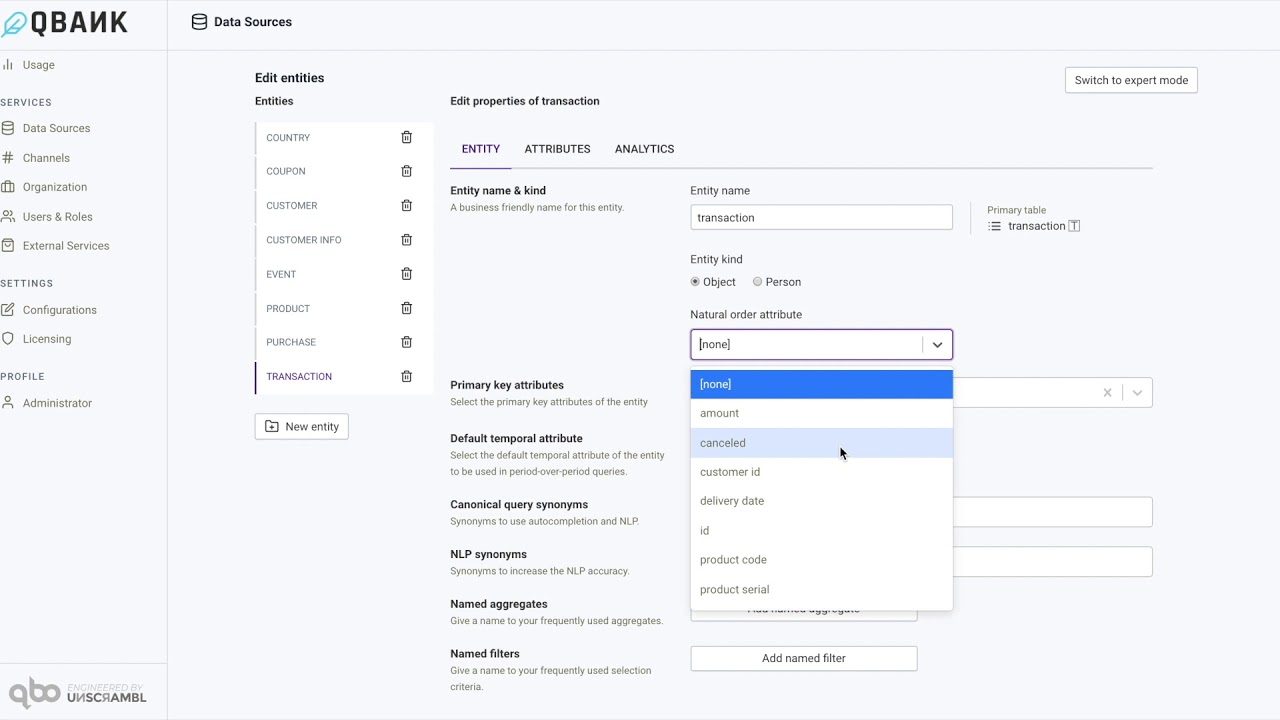
| Natural Order Attribute | This is used to control the default sort ordering when multiple entities are listed as a result of a question. For instance, if last name of a customer is selected as the natural order attribute then the output of a question like Who are the customers? would be sorted by last name |
| Primary Key Attributes | One or more attributes of the entity that uniquely identify the entity. This is a required selection and each entity instance should be uniquely identifiable using the primary key attributes. If a database schema has primary key already specified, the same would be configured as the default primary key attributes. |
| Default Temporal Attribute | Attributes of the Date or Datetime type can be configured as the default temporal attribute. When configured, this attribute is used for the trend questions and to answer questions like What is the total revenue in the last 3 months? |
| Synonyms | A set of alternative names for the entity. For instance, a customer may also be called a client or a subscriber. This assists both the NLP and guided questions by enabling alternative questions like "Who are the clients with salary greater than 100000? or Who are the customers?, where client and customer refer to the same entity. |
| Composite Date Attributes | There are instances where the database table does not have a date attribute, but instead has day, month and year attributes. This configuration allows one to create a virtual date attribute, and then potentially A set of alternative names for the entity. For instance, a customer may also be called a client or a subscriber. This assists both the NLP and guided questions by enabling alternative questions like "Who are the clients with salary greater than 100000? or Who are the customers?, where client and customer refer to the same entity set of alternative names for the entity. For instance, a customer may also be called a client or a subscriber. This assists both the NLP and guided questions by enabling alternative questions like "Who are the clients with salary greater than 100000? or Who are the customers?, where client and customer refer to the same entity it as the default temporal attribute or use it for enabling temporal analysis. |
| Named Filters | Similar to named aggregates, named filters help the administrators incorporate business terms into the bot vocabulary. Examples of these include terms like Singaporean, French being used to refer to customers from a certain country or high earners, defined as a condition over customer income. |
| Named Aggregates | Business teams often have a well-defined set of terms that they use to refer to certain summations, averages and/or conditions. Example of these include net profit, gross margin or even revenue. Such named aggregates allow typical aggregates like count, sum, minimum, maximum, average, standard deviation and distinct count along with filter conditions. |
| Referenced Entities | If you define reference relations in your QueryBot entity relationship model, this will enable generation of referenced entity filters in queries. Such reference relations are created by default based on foreign key relations when you use the QueryBot tooling to create the initial version of the QueryBot entity relationship model. For instance, say we have transactions referencing customers. This is an M-1 relationship (multiple transactions can have the same customer). In this case, each transaction is referencing a customer. In other words, the customer is the referenced entity and the the transaction is the referencing entity |
| Derived Attribute | Derived attributes are the type of attributes that are made up of other attributes. They do not actually exist in the database schema. They are calculated on the fly and presented as regular attributes. |
| Variance Analysis (Analytics) | In general terms, variance analysis is the quantitative investigation of the difference between actual and planned behavior. This also involves investigation of the factors that contribute to this difference. The goal is to identify various factors responsible for the variance/difference and take action based on this information. Let's take this example for a credit card dataset. We perform variance analysis of credit card usage or sale/revenue for the quarter and with respect to factors like location, merchant, plan, type. If we identify there is a decrease in a particular location or with a particular merchant, business can act. Same is the case with rise. |
Canonical synonyms¶
A set of alternative names for the entity. For instance, a customer may also be called a client. This assists guided questions by enabling alternative questions like “Who are the clients with salary greater than 100000?, where client refer to the same entity.
NLP Synonyms¶
qbo uses the ability of the NLP model to understand user queries with no prior training, data preparation or human-driven model building. A set of NLP alternative names for the entity are used to enhance natural language queries experience. For instance, a customer may also be called a subscriber. This assists NLP queries enabling alternative questions like “Subscriber with salary greater than 100000? or Subscriber?, where subscriber refer to the Customer entity.
Composite date attributes¶
Composite means combining attributes and if fields in the database are separate, instead of a single date or datetime field we have day, month, year fields.
Distributed databases work like this. So we combine them to get date attribute which are needed for queries where we do temporal analysis.
We have one example in our data set. Refer to the entity entity. We have fields day, month and year which can be combined to create time
attribute which will be our composite date.

This will enable us asking questions like:
What are the events that occurred after 2019-04-27?What are the events that occurred on or after 2019-04-27?What are the events that occurred before 2019-04-26?What are the events that occurred on or before 2019-04-26?
We have various filters around composite date. We will see them in the later sections.
Named filters¶
Named filters are very useful in profile tables. For example, we can define named filters like Singaporean, defined as a customer with nationality Singapore; or woman, defined as a customer with gender Female; or equity, defined as an asset with category equity. Note that the named filter (like all attributes) should be defined in singular form. The plural form is automatically used by the bot as needed.
Similar to named aggregates, one can use named filters to incorporate business terms into the bot vocabulary. Examples of these include terms like
from Europe, that are male. This enables questions like Who are the customers from Europe and Who are the customers for Europe that are male.
A number of filter types are available when configuring the named filter which includes following:
String filter
This is used to create filters for filtering out certain value of an attribute and where attribute should be of type String.
Let’s see one example of String filter of customer entity.
Related Videos
Create a named filter in qbo


Who are the customers from Korea ?Comparison filter
This is used to make a comparison while filtering out certain values of an attribute. The threshold part of the comparison filter depends on the type
of the attribute. In this example, it is of type boolean, hence the Boolean threshold is set. The other possible values are Date threshold, Date
time threshold, Double threshold and Integer threshold. The operators can be Equal, Greater than, Greater than or equal,
Less than, Less than or equal or Not equal.

Complex filter
This filter is for combining different filters with a connective. The connective can be And, Or. The example filter selects the ids between 1-10,
inclusive.
Composite date comparison filter
We can employ composite date comparison filters on composite date attributes, whose day, month and year attributes are mapped to different columns of the corresponding table.
Composite date component filter
The date and datetime values have more than one component. We can have individual filters on any of these. For example, to get the data which have April as
their month, we can use the filter as shown in the example. The time units can be either of the Day, Hour, Minute, Month, Quarter,
Week or Year.
Containment filter
For attributes of string type, we can have a list of values as a filter. This way, we can filter out the data which have a value other than the ones in that list. This is called a containment filter. The example filter only selects the data with a continent being Africa, Asia or Europe.
Composite date range filter
Filters that include composite means our fields in the database are separate; instead of a single date or datetime field we have day, month, year fields. Distributed databases work like this. So a different filter is needed for them. So, composite date range filter means we have a date range with start and end and this is shown on three different attributes of the entity as you can see below:

Composite date window filter
Window filters are rolling windows, not absolute date information is included, queries like last month, last 3 weeks are window filters. If this also
done on composite date entities it will be composite date window filter, en example:

Date component filter
Date Component filter is the filter we use when we query with a component (DayOfWeek, MonthOfYear, Year)
So when we want to query the entity that happened on a monday, or in a January, we use Date Component Filter.
This will enable us to ask queries like Products that listed on a Monday.
Existential filter
Existential filter filters the data by whether the specified attribute value is set to NULL or not. When inverted checkbox is checked, only the data where the specified attribute is set to NULL will be used. Likewise, when inverted checkbox is not checked, only the data where the specified attribute is set to some value other than NULL will be used. What are the products with a listing date? is a query you can ask about products with listing date attribute is set to some value other than NULL and likewise What are the products without a listing date? is a query you can ask about products with listing date attribute is set to NULL.

Referenced entity filter
Referenced entity filter filters the data of the current entity using a filter that runs on the entity that it references. The idea is clearer in an example. Assume we have two entities customer and country and, assume that the customer entity references the country entity. To ask about customers from Europe we can ask Who are the customers from countries with continent “Europe”?. with continent “Europe” part is a filter that runs on the country entity and we can use it to filter the data of the customer entity.
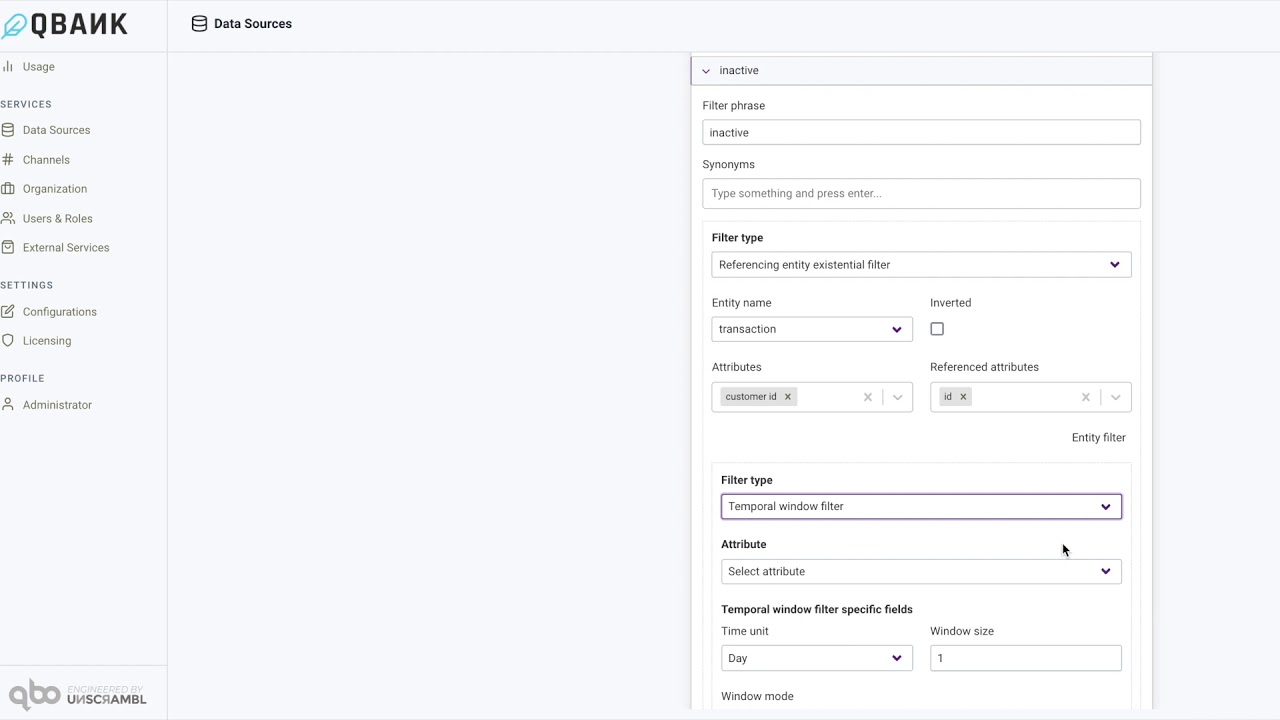
Referencing entity existential filter
Referencing entity existential filters are similar to referenced entity filters, but with the places of the entities switched. Similar to the example for the referenced entity filter, we can also ask about country entity using a filter that runs on the customer entity. To ask about countries that have at least one male customer we can ask What are the countries that have customers with gender “male”?. with gender “male” part is a filter that runs on the customer entity and we can use it to filter the data of the country entity. On the other hand, to ask about countries that have no male customers we can ask What are the countries that have no customers with gender “male”?. In order to do that we also check to inverted checkbox.
Referencing entity group filter
Referencing group filter filters data of the current entity using a filter that runs on an aggregated attribute of the entity that references it.
We can have grouping filters on the entities which reference other entities, so that we can get the queried referencing entities
For example: Who are the customers with the total amount of transactions that occurred in the last 20 days greater than 150?
Here, we know that each transaction is associated with a customer, so in this case, the transaction is the referencing entity and the customer is the
referenced one. There will be a group filter on the transaction amount and there will also be a simple filter regarding time attribute of transaction.
You can ask questions like: What are the countries with the total number of resident customer greater than 100?
We want to filter country entity here by using a filter that filters the customer entity but the filter is applied to an aggregated attribute which is the
count of the rows.
Temporal range filter
This is analogous to the Composite date range filter but these run on the datetime field already present in your database.
Temporal window filter
This is analogous to the Composite date window filter but these run on the datetime field already present in your database.
Named aggregates¶
It is basically extending aggregated attribute with a variant filter and gaining a phrase. As mentioned before, business teams often have a well-defined set
of terms (e.g. net profit, gross AUM) that they use to refer to certain summations, averages under certain filter conditions. One can not only
configure such aggregates via the UI, but also setup synonyms for the same. Specifically, one needs to provide the phrase that would be used to refer to the
aggregate, the attribute that will be aggregated (not required when aggregate function is count), the aggregate function that could be one of sum,
min, max, count, distinct count, average, standard deviation, variance, population standard deviation and population
variance, and the entity name usage criteria that could be either required or prohibited. The entity name usage, when set to required results in
support for questions like What is the average customer spending versus questions like What is the canceled amount of the transactions when the entity
name usage is required. In the aforementioned examples, average customer spending and canceled amount are named aggregates. One can also configure NLP
synonyms for such named aggregates to include additional terms that could be used to access the names aggregate.
Related Videos
Create a named aggregate in qbo


There are two other optional aspects to configuring a named aggregate, namely the normalizer configuration and the filter configuration.
The normalizer configuration is used when one wants to normalize the determined aggregate using another aggregate computed using the same data.
For instance, one as shown in the figure below for entity transaction, one can compute average customer spending by dividing the sum of
spending by the distinct number of customers in the data.


The filter configuration is used to limit the data that is used to compute the aggregate. For instance, to calculate the amount associated with
canceled transactions, one can setup a filter (canceled = true)to determine the canceled transactions. There are several other kinds of
complex filter criteria that can be configured and more about the different kinds of filters will be discussed in the later section.
Named aggregates also have Display Configuration option. Following conditions should be met to get that option enabled.
We need the aggregation function, aggregated attribute type (may be null) and normalizer for a proper check. Hence, this may affect the changes on the normalizer as well.
If the attribute type is INTEGER and the aggregation function is one of the [average, variance, std. deviation, population variance, population std. deviation], then the attribute type is set to be DOUBLE, but this can change if there is a normalizer and it has a normalized attribute type. So we cannot directly return for now.
If the aggregation function is one of the [count, distinct count], then the attribute type is set to be INTEGER, but this can change if there is a normalizer and it has a normalized attribute type. So we cannot directly return for now.
1 and 2 are mutually exclusive.
If there is no normalizer, we can return the attribute type we have found on 1 or 2.
So we have a normalizer. If it has its own normalized attribute type, it is our eventual type. Hence we return that.
If the attribute type is INTEGER up until this point, we make it to DOUBLE, because normalization is a division operation.
We are done.
You can also use multiple named aggregates with filters in the same query. For instance, let’s assume that the ‘net transaction amount’ and the ‘cancelled transaction amount’ are two named aggregates with potentially different filters. You can ask:
What is the net transaction amount and canceled transaction amount?
The ability to refine aggregation queries to add/replace named aggregates with implicit entity names is now possible. For instance:
What is the total number of the transactions?Refine and also show the net spending amountWhat is the average customer spending and canceled amount of the transactions?What is the average spending of customer ?Refine and group monthlyRefine and also show the net amountReferencing named aggregate¶
A referencing named aggregate is a calculated attribute. It references an existing named aggregate in a referencing entity. An attribute of this kind is calculated by grouping the data in the referencing entity by the current entity and running the aforementioned named aggregate for each of these groups.
For example, We have a named aggregate named net spending amount in the transaction entity. This named aggregate sums the amounts that are not cancelled in the transaction entity. We declare an attribute named spend in the customer entity. We declare that this attribute references the net spending amount named aggregate in the transaction entity. Values of this attribute are calculated by grouping the transaction entity by the customer and aggregating net spending amount for each of these groups. The result gives the total amount that is spent by each customer. We may choose to display this attribute along with the other attributes of the customer entity.

Referenced entities¶
Reference is a relationship between entities in which one entity designates, or acts as a means by which to connect to or link to, another entity. The first entity in this relation is said to refer to the second entity.
Reference tables are a special type of profile tables. They are most useful when they are joined with profile, transaction or aggregate tables. For example, there might be a location reference table that gives the latitude and longitude of each city mentioned in another table. Or a product reference table that gives details about products mentioned in sales transactions or inventory table.
Some best practices for dealing with
Reference tables usually have a primary key that is used for joining with the other tables. For example, this could be a city name or a product id.
Reference tables can be specified as reference relations for other entities.
It is often useful to add attributes in the reference tables as attributes in other tables to simplify the query construction.
For this we need to add new entities. You can refer to the next few sections on how we can add or delete entities. Let’s see how these can be created using user interface.
Follow below steps to configure Referenced Entities:
Select
Entityfrom the added list of the entities on the left side for which you want to configureReferenced Entities.Scroll down to the
Referenced entitiessettings.Click on
Add reference relationsettings.Select
Referenced Entityfrom the drop down.Select attribute from the drop down and provide phrases for referenced and referencing entities.
Let’s see a few examples of Referenced Entities.
Look at the schema of the
CUSTOMERandCOUNTRYentities. EntityCOUNTRYhas an attributenameand entityCUSTOMERhas attributescountry_of_birthandcountrythat can be referenced. Here we will updateCOUNTRYas referenced entity inCUSTOMERentity.


TRANSACTION and PRODUCT. Entity TRANSACTION has an attribute product_code and entity
PRODUCT has an attribute code that can be referenced. Here we will update PRODUCT as referenced entity in TRANSACTION entity.

Later you can ask questions like:
Who are the customers born in country Korea?Who are the customers in countries with population greater than 1000?Transactions have product description hat?Products making transactions with quantity greater than 9?Multiple level nesting is also supported. For instance:
What are the transactions from customers in countries with population greater than 1000?
Note that these go from transactions to customers to countries.
Deleting an entity¶
There might be some scenarios where we need to remove the entity added during the setup which is not needed anymore. Then we have an option to delete an entity. Follow the below steps to delete an entity:
Select database from the added
Data SourcesClick on the
Editbutton on the top right corner.Click on the
Deleteicon to delete an entity. For exampleCUSTOMER.

After deleting click
Save draftand thenActivate draft.
Adding a new entity¶
There might be some scenarios where we need to add more entities from the database which were not added during setup. Then we have an option to add an entity. Follow the below steps to add an entity:
Select database from the added
Data SourcesClick on the
Editbutton on the top right corner.Click on the
New entityicon to add an entity. For examplePURCHASE.Select table name from the drop down and provide entity name.
After adding click
Save draftand thenActivate draft.

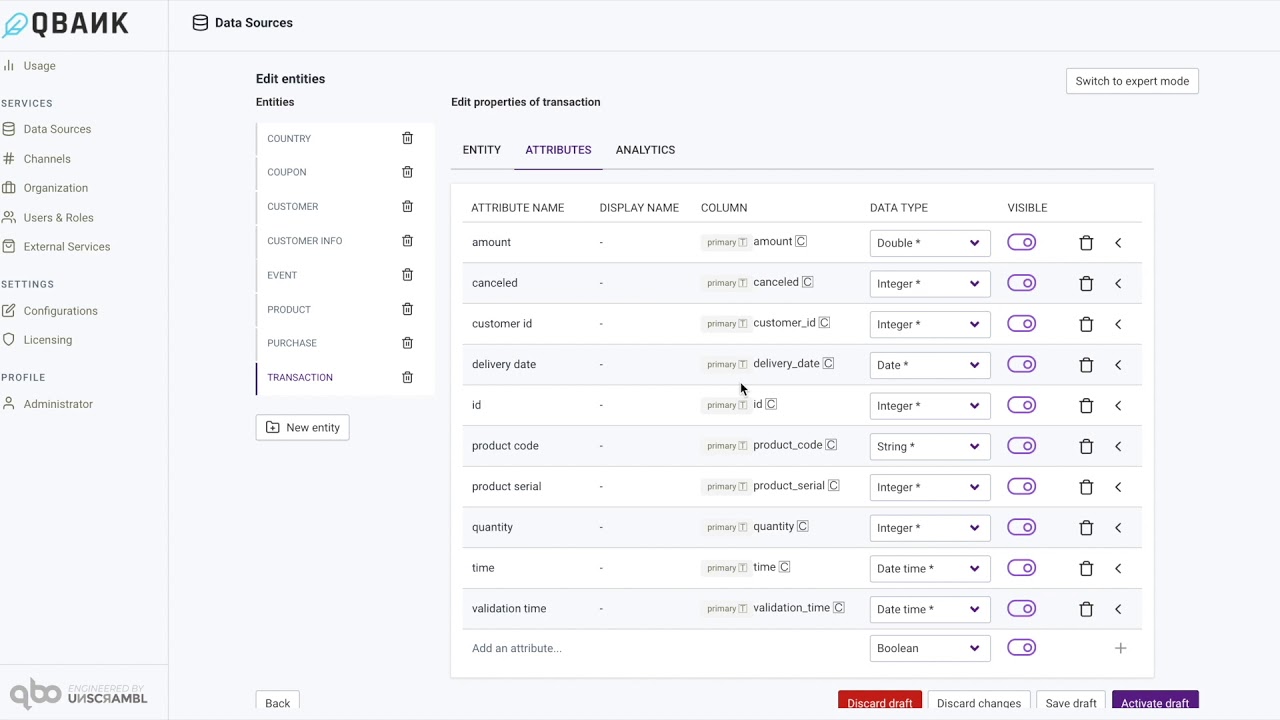
Attributes of an entity¶
An entity can have 1 or more attributes. Such attributes can come from the primary table, or can come from other tables by means of specifying the appropriate relationship between the primary table and the table in question. When adding attributes from a table other than the primary table, it is important that the relationship conditions result in exactly 1 row being fetched from the target table. In a typical database schema definition, this is the case when there is a foreign key in the primary table that maps to the primary key in the target table.
Attribute with a path of foreign key relation
This type of attribute does not come from a column of the primary table. Instead, it comes from a column of a table related to the primary table. We can declare this type of attribute only if there is a foreign key relation path between the two tables, and all of these relations is either one-to-one or many-to-one.
For example:
We declare the country population as one of the attributes of the customer entity. We declare that the population attribute comes from the population column of the country table. Then we declare the foreign key relation path for it, which is essentially the table join conditions in order to get the desired column. The foreign key relation path for this attribute would be: [(customer.country -> country.name)]. We can do this because for each customer there is only one country.
We can also chain foreign key relation paths. For example, We declare country population as one of the attributes of the transaction entity. We declare that the population attribute comes from the population column of the country table. Then we declare the foreign key relation path for it, which is essentially the table join conditions in order to get the desired column. The foreign key relation path for this attribute would be: [(transaction.customer_id -> customer.id), (customer.country -> country.name)]. We can do this because for each transaction there is only one customer, and for each customer, there is only one country.

Note
There might be some cases where we have a foreign key relation but we do not want it to be validated then Referenced columns key validation disabled
can be checked.

For a selected entity, the attributes tab lists all the attributes associated with the entity and provides an easy interface for editing various configurations associated with an attribute.

Related Videos
Logical data model and entities
The concept of primary key and value substitute
Path of foreign key
One can edit the name of the attribute and it does not need to be column name as retrieved from the database.
This is achieved by clicking on the name of the attribute and the same becomes editable. The source column and the table name,
primary or otherwise, from the data source is displayed under the column heading.
One can change the Data Type of the attribute as long as the same is compatible with the type in the backing data source.
For instance, an Integer attribute from the backing data source can be mapped to a String, etc. The interface throws an error
when in incompatible types are detected.
An entity may have several attributes, and if one wants to limit the attributes shown by default, in response to a query like
Who are the customers or What are the transactions, then one can unset the Visible toggle for the attributes that need
to be hidden. Please note that the user can still explicitly request for such attributes using a query like What is the age of the
customers - and age will show up, even if the attribute is marked as not visible.
There are several other configurations that are enabled for an attribute, and the same are accessible by clicking on the chevron on the right of each attribute listing.
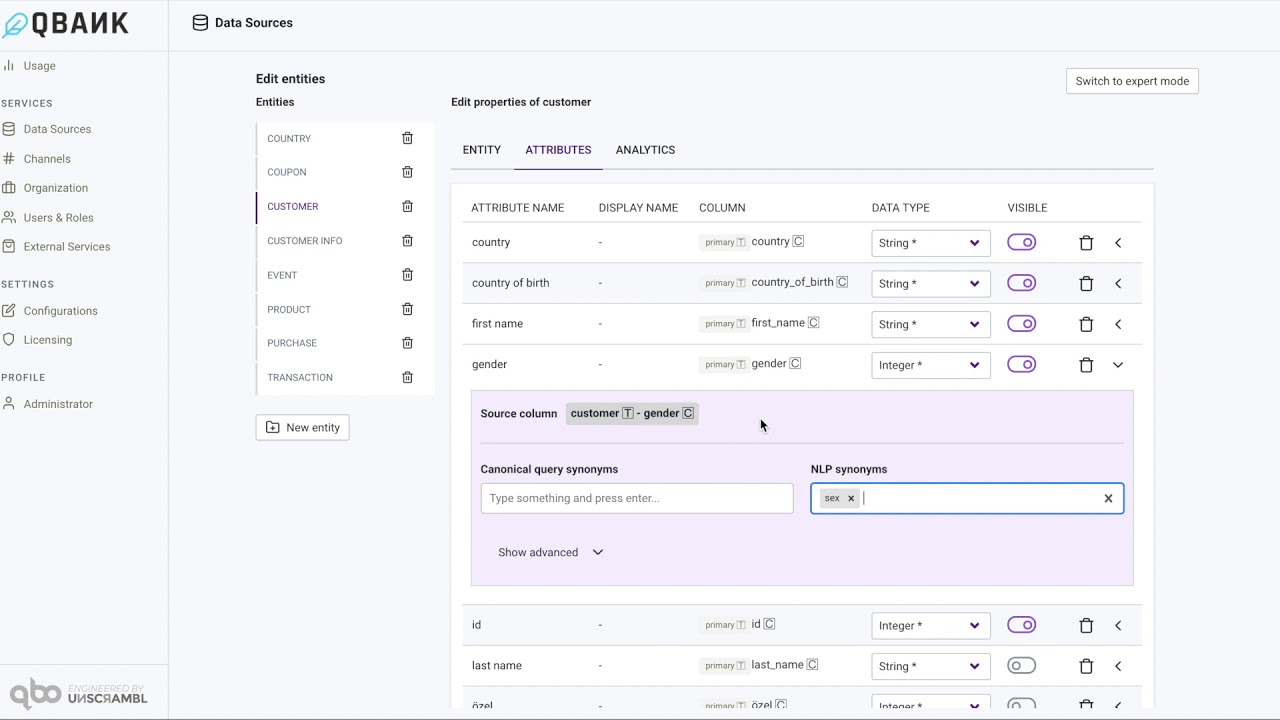
Value Substitutes¶
In the expanded configuration interface for an attribute, for attributes with String data type one can add Value Substitutes.
This can, for instance, be used to map 0 to Female and 1 to Male - even if the gender column is of Integer type in the database.
From the business perspective one can ask a query like Who are the customers with gender Female even when the database has 0 and 1 in
the gender column.

Grammar generation configuration¶
The grammar generation configuration is supported for Boolean, Numerical (i.e. Integer, Decimal, Double, Percent and Currency),
String and Temporal (i.e. Date and ``Datetime) attributes. The same is detailed below for each data type.
Boolean attributes support positive and negative phrases. These phrases help us to create the same query in different forms.
For example, the following query is the one without any configuration - What are the transactions that are canceled? In this query,
canceled is a Boolean attribute. Now, if one would like to have the wording state in the query then for this attribute, we can add
the configuration which has not in canceled state for the negative phrase and in canceled state for the positive phrase. Now the same
query can be asked with the phrases we have provided in the configuration: What are the transactions in canceled state?

For attributes with Numeric data type a number of grammar generation configurations are available. The Between phrase can be used
to configure the phrase used to find a number between two values. The Equality phrase, like priced exactly, as shown in the screenshot
below adds a more human touch to the question phrasing. This configuration permits us to ask questions like What are the products priced
exactly 10.0? instead of the default What are the products with price 10.0?. Other configurations like the Greater than or equal phrase,
Greater than phrase, Inequality phrase, Less than or equal phrase and Less than phrase
help refine the phrasing further.

The Attribute type for aggregations is almost always summable for the numeric attributes, which means that the attribute can be summed.
For some cases, like when an id is an integer or a product code is an integer, we may want to limit it to be only countable or comparable.

For attributes with String data type, similar to the grammar generation configurations for the Numeric attribute types, a number of
configuration phrases are available that help us humanize the queries to be asked. String attributes also allow an additional configuration
that enables custom sort order. This custom sort order is useful for scenarios where the alphabetical sort of the String attribute is counter-intuitive.
For instance, consider a segment attribute with values High Value, Mid Value and Low Value. These will get sorted as High Value, Low
Value and
Mid Value in ascending order and business user may not like the fact that Low Value appears in between High Value and Mid Value. Custom sort
configuration alleviates this problem.

For Temporal attributes like the Date and the Datetime attributes allow the configuration of a Connecting phrase. For instance, the attribute
configuration below allows one to ask a query like What are the products that listed after 2019-04-27? instead of the default question What are the
products with listing date after 2019-04-27?.

Display configuration¶
For Numeric attribute types other than Currency, one can set Number format, Number postfix and Number prefix configurations.
This way, we can prepend a tag to the number or append a tag to the same number as the labels in the visualizations.
The configuration above makes for example 51.57M label to be displayed as counting 51.47M people.

For Currency one can additionally set the currency code, so that each value for that attribute has that currency code added to the labels in
the visualizations.
The configuration above makes for example 51.57M label to be displayed as making 51.47M USD profit.

Synonyms¶
One can also setup synonyms for referring to an attribute. For instance, one can setup pay as a synonym for salary, and as a result questions like
What is the salary of the customers and What is the pay of the customers will return the same response.

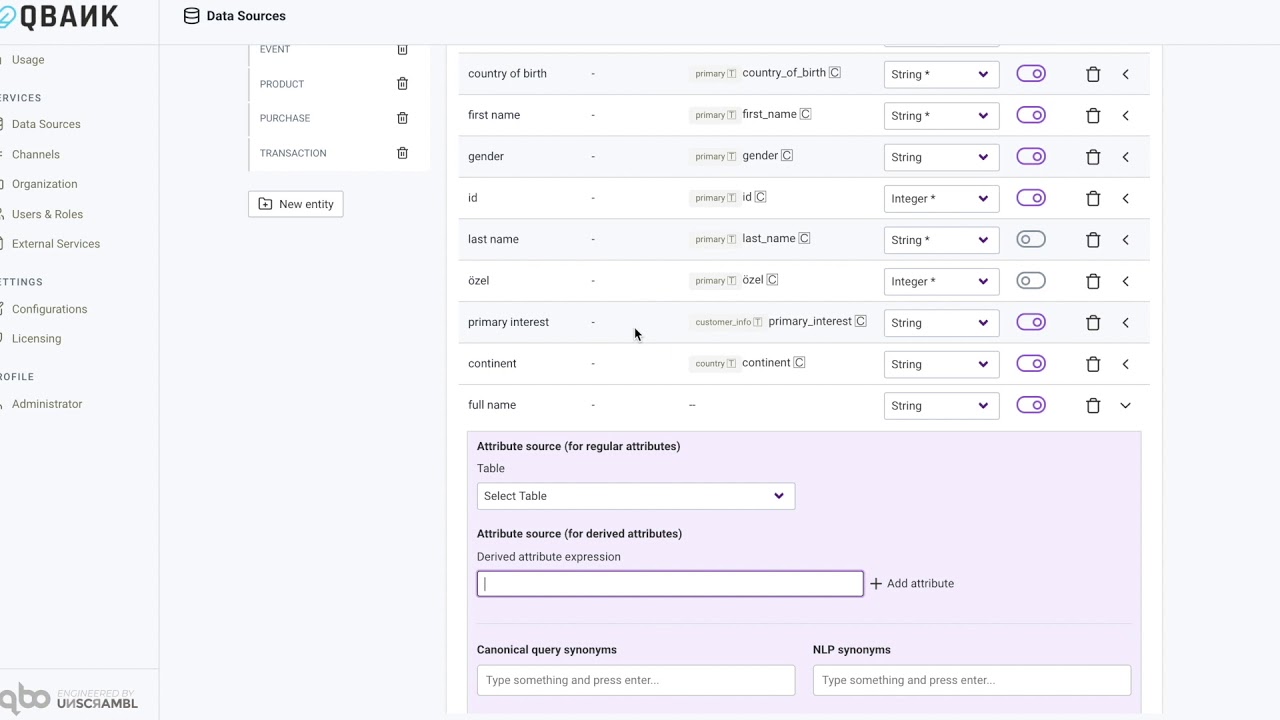
Derived attribute¶
Derived attributes are the type of attributes that are made up of other attributes. They do not actually exist in the database schema. They are calculated on the fly and presented as regular attributes. They are distinguished from the regular attributes by the derivedAttributeExpression field. If this field is filled, then we assume the attribute is a derived attribute. Another distinguishing point for derived attributes is that they do not have an attribute mapping defined for them. This is because they are calculated attributes and not physical ones. This also means they do not have value substitutes or path of foreign keys defined for them.
The expression for the derived attribute is a string written in the Unscrambl Chai Expression Language (UEL). We try to parse this expression and generate the SQL that is equivalent to it. With UEL we are able to support binary arithmetic operations, ternary operations, value literals as of now, and support for the remaining operations or functions is on the way.
Examples of derived attributes with expressions:
an attribute named profit can be defined as revenue - costan attribute named unit price can be defined as amount / quantityan attribute named price over 100 or 0 can be defined as price > 100 ? price : 0an attribute named quantity doubled can be defined as 2 * quantity
Let’s see an example in qbo. Where when new attributes are derived using existing attributes.

Related Videos
The concept of derived attribute in qbo
Analytics that can be performed on an Entity¶
First, let’s define a few basic concepts related to analytics:
Metric: Any measurable quantitative value in the dataset like total count, average revenue. Metrics are usually computed by aggregating values from one or more attributes.
Dimension: Any attribute that can be used for grouping the entity. Usually, these are string attributes like city, team etc.
Variance queries allow comparing the values of a metric (also called behavioral aspect) between two different values of a dimension (also called a related aspect).
Qbo performs variance analysis on the metric by:
Analyzing the key reasons for the differences. qbo digs into different dimensions (or aspects) that are related to the metric to identify the most significant values that explain the difference between the two values of the metric.
Ranking the values of each dimension based on the absolute change, percentage change, and significance of the change in comparison to other values in that dimension. qbo presents the top k values across all available dimensions along with additional information about other related metrics.
There are two common types of variance queries:
Comparison based on a time attribute
This is the most common kind of variance query, and is commonly used to analyze why some metric has increased or decreased in a given time period compared to some baseline. There are two different ways of defining the baseline:
Comparison of the value of a metric between two different periods of time. Note that it is possible for the two different periods to be of different lengths of time – in this case, qbo just warns about this and proceeds with the analysis. Examples are: Date attribute name
Compare the spent amount in the last 3 days with the previous 3 daysCompare the spent amount in the current week with the previous 3 daysCompare the spent amount in the last 3 weeks including this week with the previous 3 weeksCompare the spent amount in the last 2 months including this month with the previous 3 weeksCompare the spent amount in the current week with that in between 2016-08-01 and 2016-08-02Comparison of the value of a metric on a given time period with an average. In this case, the average is computed on the full dataset, and it can be a daily, weekly, monthly, quarterly or yearly average depending on how the time period is defined. Examples are : Compare the spent amount on 2016-07-18 with the average In this case, we compare the spent amount on a given day with the daily average over the whole dataset. Phrase the average is interpreted as daily average by default. Compare the spent amount in the last 2 quarters including this quarter with the weekly average
In this case, we compare the weekly average of the spent amount in the last 2 quarters including the current quarter so far, with the weekly average over the whole dataset. The Average period specified for the planned period is used for both time periods.
Comparison based on a non-time attribute This allows us to compare the value of a metric between different products, customers, regions or other non-time dimensions, and analyze the key factors behind the difference. Examples are :
Compare the spent amount of customer Maryjane Doyle with that of customer Tianna StanleyCompare the spent amount of customer "Maryjane Doyle" with that of customer Tianna StanleyA time period filter can be applied to these queries. Eg:
Compare the spent amount of customer Maryjane Doyle with that of customer Tianna Stanley in
the last 3 weeksCompare the spent amount of customer Maryjane Doyle with that of customer Tianna Stanley on
or after 2020-04-10Let’s take an example to understand how this can be configured in qbo:
Go to the
Analyticssection of the entity for which you doVariance Analysis.If
Date attribute nameis provided time based comparison will be enabled.If
Only categorical aspectsbutton is checked, you cannot set anINTEGERattribute as aspect (onlySTRINGorLOCATION_NAME), if it is unchecked they can beSTRING,LOCATION_NAMEandINTEGERtype.Configure
Aspectsby selecting attributes from the dropdown and giving them a name.Configure
Behavioral aspectsand map to theAspects.

Here we can see that for entity transaction, metrics (Aspects) number of transactions and total amount can be compared with respect to dimensions
(Behavioral aspects) product code and customers
Here you can see that user John is able to compare the total amount of transactions with respect to time and product code.

Note
Named aggregates can be used as variance behavioral aspects. At this time, there are some restrictions on the named aggregates that can be used as variance behavioral aspects.
Their aggregation function is sum or count.
All the attributes having the attribute type string, integer, and location name can be regarded as related aspects.
For manually added behavioral aspects, the querybot validates that the names of the behavioral aspects are the same as a named aggregate phrase of the same entity. If a named aggregate phrase is found that is equal to a behavioral aspect name, the querybot validates that the behavioral aspect has the same attribute name, the same aggregation type(behavior), and the same normalizer of that named aggregate.
Save, Deploy & Reload¶
As any process exhibits various behaviors and goes to various stages before we finalize the blueprint or the outline like building, testing and deploying
similarly at various points while you are editing and making changes to the entities, attributes and their configurations in the Data Source Configuration,
you can decide to either keep them or reject them. And even if you are keeping the modifications then you must make them reflect in the conversations.
To attain this lets see the whole behavior or the cycle of managing the revisions or modifications being done. This process involves following steps:
Edit Draft –> Save Draft or Discard Changes –> Activate Draft or Discard Draft –> Reload

Let’s see steps below how to do this:
Click on the
Eyeicon to view the data source you want to edit.

Click on the
Editbutton to start editing configurations.After making all the necessary changes, always remember to click on the
Save draftbutton to save your changes.

You will see a message
Draft added successfullyif all the changes are saved successfully.If you want to go back to the data sources click on the
Backbutton.Now you will see an added icon of the draft you were working on in the data sources and you can click on the
Editicon to make further more changes.

After all the changes made you can again click the
Save draftbutton followed by theActivate draftbutton.
You will see a message
Draft activated successfullyif the draft activated successfully.At last you need to reload your data sources.
You will see a message
Query bot server reloaded successfullyif the draft reloaded successfully.Similarly we can
Discard changesandDiscard draftif needed.
Data access roles¶
We can define roles to restrict access to data sources means restricting entity access or attribute access for a set of users. That means data source
based roles.
In other words, a role allows a user to use a particular functionality within the solution so that user can perform a task or set of tasks.
There could be a scenario where we need to restrict some level of data access from the developer where we might need to hide some critical information
from the developer or for an instance we need to reveal a particular set of data to the analyst. There comes Data Access Roles in the picture.
Data access role configuration is accessible under the Data Sources link, under the DATA ACCESS ROLES tab. Data access roles are used to restrict the
access of a user to certain entities. Such access restrictions can be further extended to the attributes of the entities, and even further, to limit access
based on the value of the attributes.

For instance, one can create an Developer role that has access to customer and product entities only.

Let’s give this role Developer access to two entities that is customer and product.

Now, one can further restrict the access of the Developer role and make the attribute gender not accessible to this role.

Finally, one can restrict the access of the Developer role to product entities with code equal to US-HEALTH-01.08.

Hovering on the role name will give you an icon to delete the role.

Developer role has been defined with all the restrictions applied. Now we will assign one user under this role and see what is accessible to the user.
For any user let’s suppose John here update the Data access role in the User Access Management from Access All to Developer.

Now click on the Save Changes button to see the updated role of the user.

Now sign-in for user John and test for queries for entities.

Here you can see that user John is not authorized to ask questions on event entity.

So that’s a very beneficial part where depending on the data, the use case and criticality of the data restrictions can be made.